 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal2Sim in HOI: Toward Physically Plausible HOI Reconstruction from Monocular Videos
May 14, 2026Recovering 4D human-object interaction (HOI) from monocular video is a key step toward scalable 3D content creation, embodied AI, and simulation-based learning. Recent methods can reconstruct temporally coherent human and object trajectories, but these trajectories often remain visual artifacts while failing to preserve stable contact, functional manipulation, or physical plausibility when used as reference motions for humanoid-object simulation. This reveals a fundamental interaction gap: HOI reconstruction should not stop at tracking a human and an object, but should recover the relation that makes their motion a coherent interaction. We introduce $\textbf{HA-HOI}$, a framework for reconstructing physically plausible 4D HOI animation from in-the-wild monocular videos. Instead of treating the human and object as independent entities in an ambiguous monocular 3D space, we propose a $\textit{human-first, object-follow}$ formulation. The human motion is recovered as the interaction anchor, and the object is reconstructed, aligned, and refined relative to the human action. The resulting kinematic trajectory is then projected into a physics-based humanoid-object simulation, where it acts as a teacher trajectory for stable physical rollout. Across benchmark and in-the-wild videos, $\textbf{HA-HOI}$ improves human-object alignment, contact consistency, temporal stability, and simulation readiness over prior monocular HOI reconstruction methods. By moving beyond visually plausible trajectory recovery toward physically grounded interaction animation, our work takes a step toward turning general monocular HOI videos into scalable demonstrations for humanoid-object behavior. Project page: https://knoxzhao.github.io/real2sim_in_HOI/
SoK: Robustness in Large Language Models against Jailbreak Attacks
May 06, 2026Large Language Models (LLMs) have achieved remarkable success but remain highly susceptible to jailbreak attacks, in which adversarial prompts coerce models into generating harmful, unethical, or policy-violating outputs. Such attacks pose real-world risks, eroding safety, trust, and regulatory compliance in high-stakes applications. Although a variety of attack and defense methods have been proposed, existing evaluation practices are inadequate, often relying on narrow metrics like attack success rate that fail to capture the multidimensional nature of LLM security. In this paper, we present a systematic taxonomy of jailbreak attacks and defenses and introduce Security Cube, a unified, multi-dimensional framework for comprehensive evaluation of these techniques. We provide detailed comparison tables of existing attacks and defenses, highlighting key insights and open challenges across the literature. Leveraging Security Cube, we conduct benchmark studies on 13 representative attacks and 5 defenses, establishing a clear view of the current landscape encompassing jailbreak attacks, defenses, automated judges, and LLM vulnerabilities. Based on these evaluations, we distill critical findings, identify unresolved problems, and outline promising research directions for enhancing LLM robustness against jailbreak attacks. Our analysis aims to pave the way towards more robust, interpretable, and trustworthy LLM systems. Our code is available at Code.
CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
Jan 15, 2026In this paper, we find that the generation of 3D human motions and 2D human videos is intrinsically coupled. 3D motions provide the structural prior for plausibility and consistency in videos, while pre-trained video models offer strong generalization capabilities for motions, which necessitate coupling their generation processes. Based on this, we present CoMoVi, a co-generative framework that couples two video diffusion models (VDMs) to generate 3D human motions and videos synchronously within a single diffusion denoising loop. To achieve this, we first propose an effective 2D human motion representation that can inherit the powerful prior of pre-trained VDMs. Then, we design a dual-branch diffusion model to couple human motion and video generation process with mutual feature interaction and 3D-2D cross attentions. Moreover, we curate CoMoVi Dataset, a large-scale real-world human video dataset with text and motion annotations, covering diverse and challenging human motions. Extensive experiments demonstrate the effectiveness of our method in both 3D human motion and video generation tasks.
Dynamic Path Navigation for Motion Agents with LLM Reasoning
Mar 10, 2025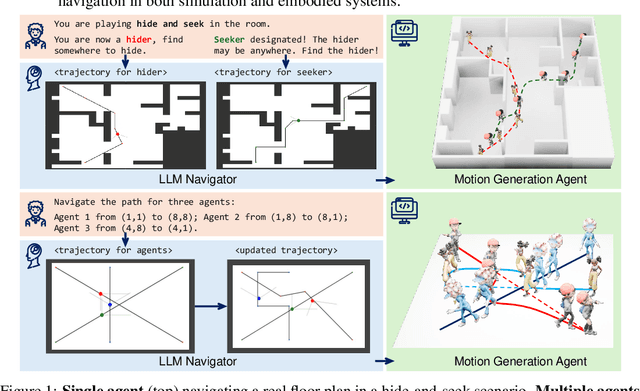
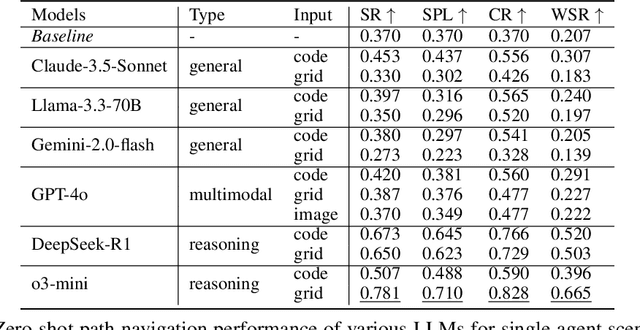
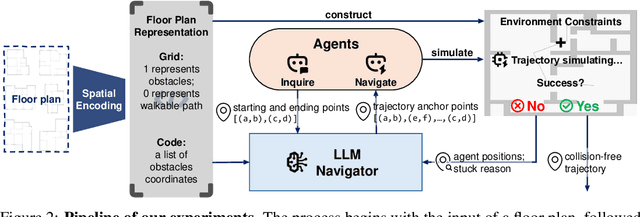
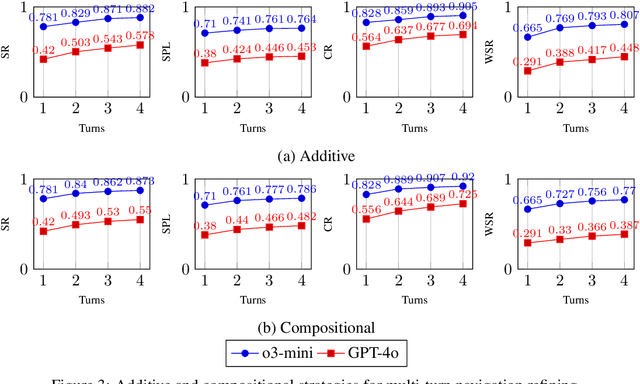
Large Language Models (LLMs) have demonstrated strong generalizable reasoning and planning capabilities. However, their efficacies in spatial path planning and obstacle-free trajectory generation remain underexplored. Leveraging LLMs for navigation holds significant potential, given LLMs' ability to handle unseen scenarios, support user-agent interactions, and provide global control across complex systems, making them well-suited for agentic planning and humanoid motion generation. As one of the first studies in this domain, we explore the zero-shot navigation and path generation capabilities of LLMs by constructing a dataset and proposing an evaluation protocol. Specifically, we represent paths using anchor points connected by straight lines, enabling movement in various directions. This approach offers greater flexibility and practicality compared to previous methods while remaining simple and intuitive for LLMs. We demonstrate that, when tasks are well-structured in this manner, modern LLMs exhibit substantial planning proficiency in avoiding obstacles while autonomously refining navigation with the generated motion to reach the target. Further, this spatial reasoning ability of a single LLM motion agent interacting in a static environment can be seamlessly generalized in multi-motion agents coordination in dynamic environments. Unlike traditional approaches that rely on single-step planning or local policies, our training-free LLM-based method enables global, dynamic, closed-loop planning, and autonomously resolving collision issues.
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
May 28, 2024



Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM